AMD unveiled its XDNA 2 NPU core architecture, delivering 50 TOPS of AI processing performance and up to ×x projected power efficiency. The NPU is optimized for matrix-math and vector operations, featuring a wider matrix engine and a new data type, block floating point. AMD also acquired Silo AI, a leading private AI lab, for $665 million.
One thing you can say about AMD, it is not a reactive company. Not always first to market, but when it does enter, it does so on its own terms and time.
The company announced its powerhouse Instinct MI300X platform, modules, AIB, and GPU a year ago and has been filling sockets and data centers with it since. At Computex, it showed the second-generation MI325X with CDNA next architecture, part of the new MI300 series due in December.
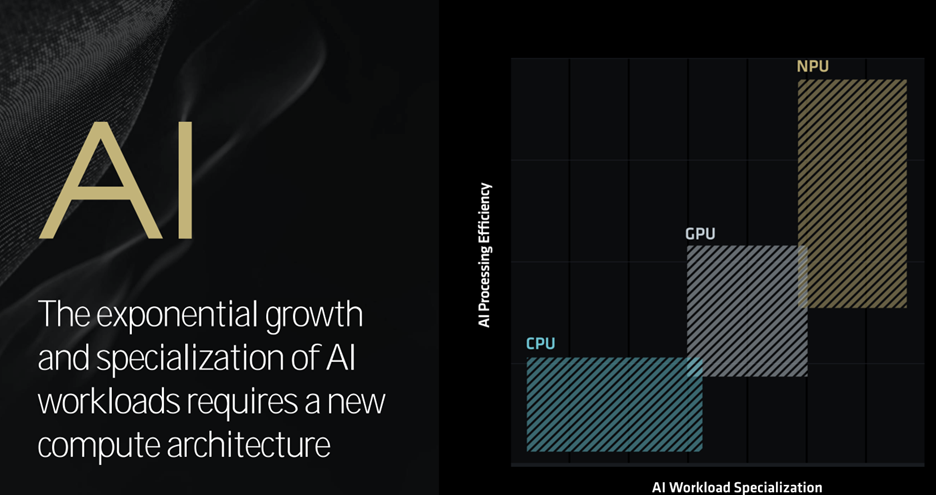
The company also revealed its forthcoming XDNA 2 NPU core architecture, which delivers 50 TOPS of AI processing performance and up to 2× projected power efficiency.
Last week, at its Tech Day conference in Los Angeles, the company provided more information on the new NPU. The new (third-gen) NPU will be embedded in the new Ryzen Zen 5 Strix Point series of x86 CPUs. AMD postulated that if the x86 CPU Zen 5 represented a base (1×) of AI model performance per watt, then an RDNA 3.5 iGPU would be eight times that, and AMD’s XDNA 2 NPU would be 35 times it. All three processors will be in AMD Ryzen AI.
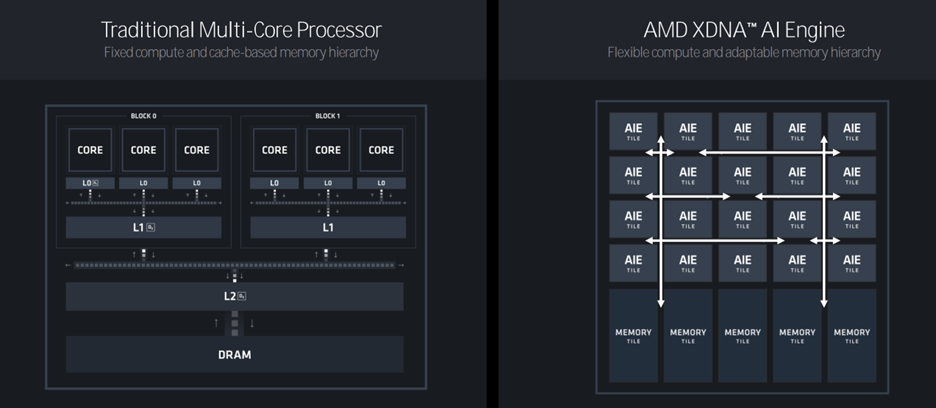
AMD says their NPU is optimized for matrix-math and vector operations. With XDNA 2, the company introduced two new capabilities: a wider 8×4 matrix engine (that can also be configured to run 4×4) and a new data type, block floating point, which offers 8-bit performance with 16-bit accuracy. AMD claims most AI applications use 16 bit, which requires quantization to reduce it to 8 bit to improve performance. However, doing that causes a loss of accuracy and, in some situations, requires a second pass to improve the accuracy. AMD says their block floating point data type eliminates the need for that second pass.
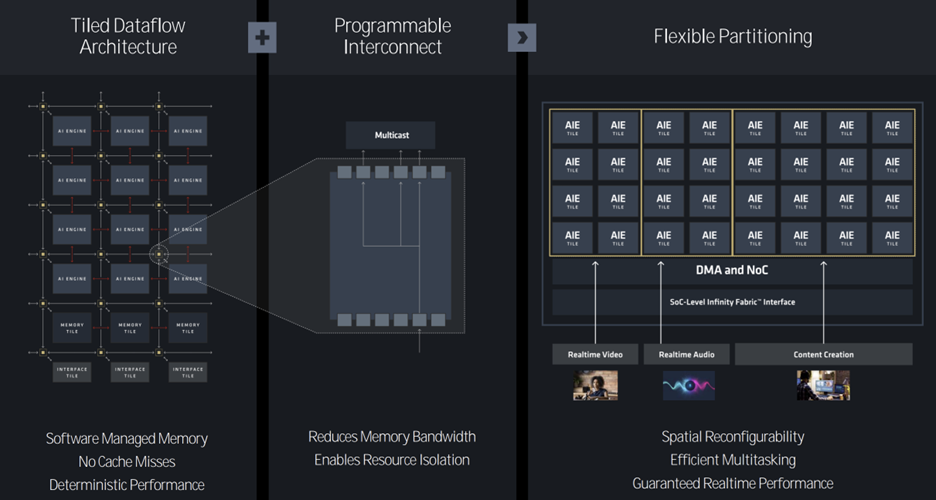
AMD also claims their DMA controller pushes the data to the core, thereby reducing cache misses (which also require a second pass or an accuracy loss). And, the NPU uses memory titles offering customization opportunities.
Partitioning the NPU can reduce latency, and as an example, the two left two-wide core sets, shown in Figure 2, could be used for video and audio. The NPU can also do time slicing (for temporal filtering).
AMD has shown Microsoft its block floating point data-type scheme as an additional capability to its Copilot+.
Last but not least, AI operators can be created to enhance specific applications. LUTs can be added for non-linear functions.
To round out the company’s thrust into the AI arena, AMD announced the acquisition of Silo AI, the largest private AI lab in Europe, in an all-cash transaction valued at approximately $665 million. Silo does language translation LLMs.
Riding high
All the AI hardware and software announcements caught the attention of Wall Street and market makers. AMD’s share price jumped after the Silo AI announcement, and Wells Fargo and Bank of America pegged AMD’s share price in the $205 to $265 range by the end of the year (as of this writing, it was at $181).