Microsoft is reducing a portion of the frame using level of detail (LOD), which enhances efficiency and reduces memory usage. By iteratively utilizing small portions of the bounding volume hierarchy (BVH) structure, Microsoft’s method minimizes GPU memory usage and the number of ray-tracing checks required. This strategy is particularly beneficial for fast-paced gaming environments, where performance optimization is crucial.

What do we think? Microsoft has come up with a clever way to speed up ray tracing for games. Borrowing techniques used for VR to improve frame rate, the same concept can speed up ray tracing at the expense of pure photorealism, which isn’t needed in a game.
Is ray tracing in games about to get faster?
The trick (all computer graphics is a trick) that makes DLSS, XeSS, and FSR 3 work is reducing the resolution before ray tracing is performed. Ray tracing is very resolution-sensitive.
AMD, Intel, and Nvidia (AIN) reduce the whole scene or frame. Microsoft proposes to reduce a portion of the frame using level of detail (LOD). That is the same trick AIN used to speed up the refresh rate of VR and reduce VR sickness. It’s a clever approach because no one looks at everything in a frame, especially anyone playing a fast-moving FPS. Gawk, and die, is the saying.
LOD has another benefit—it’s not GPU-dependent—and it uses less memory.
With the exception of Adshir/Snap’s ray-tracing approach, all others use bounding boxes in a bounding volume hierarchy (BVH) that surrounds different parts of a scene’s geometry.
Microsoft bypasses the utilization of the complete BVH simultaneously (which eats up a lot of cycles). Instead, it employs small portions of the BVH iteratively, storing details of the usage and the relevant BVH component (referred to as a node) in two lists within the GPU’s memory. With each subsequent frame, the ray-tracing algorithm refreshes these lists, ensuring that only the nodes essential for the scene (while disregarding the non-visible or unnecessary ones) occupy space in the VRAM.
Mark Grossman, a senior architect in Microsoft’s research division, authored the patent and provided a block diagram of the process within it.
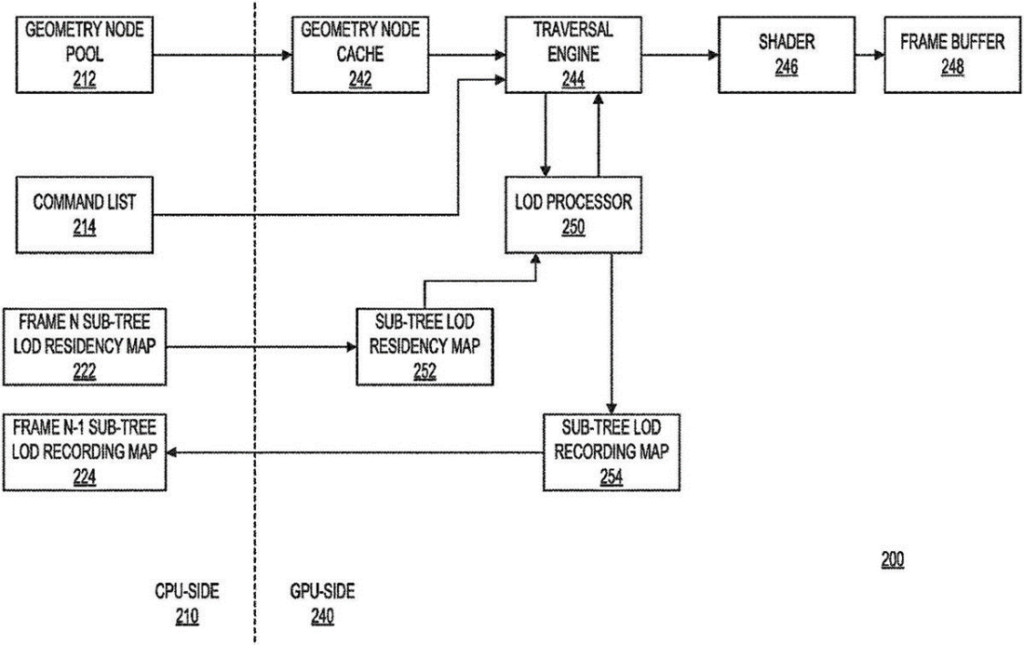
Microsoft’s approach reduces the demand on the AIB’s memory and the GPU’s cache. it also reduces the number of ray tracing checks (instances) needed. Instead of continuously going over the entire BVH structure to find ray-object interactions, only those in the residency and recording map need to be examined.
The GPU side (240) of the graphics processing system (200) may include geometry node cache (242), traversal engine (244), shader (246), frame buffer (248), LOD processor (250), sub-tree LOD residency map (252), and sub-tree LOD recording map (254).
It’s a clever approach for a gaming environment. It wouldn’t be any faster, or very much faster, for physically accurate rendering of, say, a shiny, curvy car because rays are rays in such a situation, no matter how you slice and dice them. But in a fast-paced, high frame rate game, you can take some shortcuts, and no one is going to complain.
The next step will be for Microsoft’s clever marketing people to name/brand the technique. Fast RT or something like that. Certainly, there will be no series of SS in it, even if it does use supersampling.
And, there won’t be any intermediate AI-generated frames. That’s really going to challenge the marketing people—a new technique that you can’t apply the term AI to—how will they sell it?
It’s a pretty fascinating patent, and if you’re into GPU architecture or ray tracing, you should check it out.